Stream-Processing als Voraussetzung für die Wertschöpfung aus IIoT-Daten5G-Mobilfunk reicht nicht im Industrial Internet of Things
14. März 2019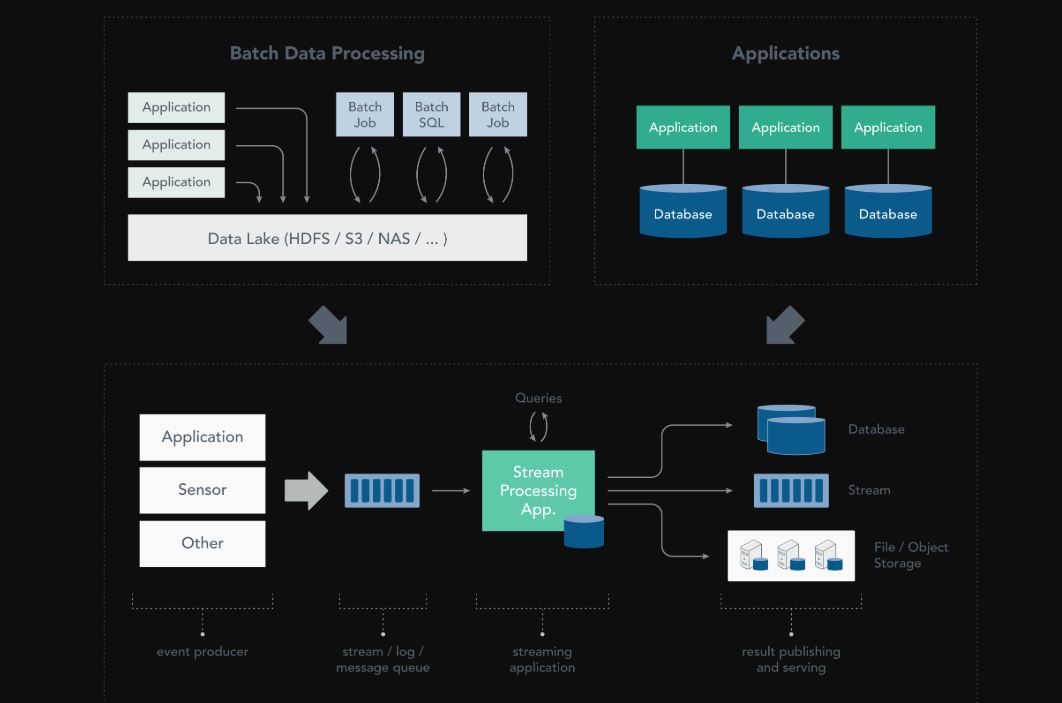
Schnelles „5G“ alleine bringt der Industrie nichts, wenn IoT-Daten zu langsam verarbeitet werden. Zu diesem Ergebnis kommen viele Experten aus dem Bereich des industriellen Internet der Dinge (IIoT). Dabei hilft auch nicht der Einsatz der 5G-Mobilfunktechnologie weiter. Erst wenn das Stream Processing zum Einsatz kommt, wird die Verarbeitung von Datenströmen nahezu in Echtzeit ermöglicht – und das ist die Voraussetzung für die Wertschöpfung aus IIoT-Daten.
Beim Stream Processing handelt es sich um die Verarbeitung von Daten „in Bewegung“, sprich die Bearbeitung der Daten direkt bei ihrer Erzeugung oder wenn sie empfangen werden. Die meisten Daten entstehen als kontinuierliche Streams: Dazu gehören Sensor-Ereignisse, Benutzeraktivitäten auf einer Website, Finanzhandel usw. – all diese Daten werden als eine Reihe von Ereignissen im Laufe der Zeit erzeugt. Bislang – also vor dem Strteam Processing – wurden diese Daten zunächst in einer Datenbank, einem Dateisystem oder anderen Formen der Massenspeicherung abgelegt. Erst danach fragen die zugehörigen Anwendungen die Daten ab oder aber sie führen an ihnen die gewünschten Berechnungen aus.

Das Stream Processing dreht dieses Paradigma um: Anwendungslogik, Analysefunktionen und Abfragen sind kontinuierlich vorhanden, und die Daten fließen auch kontinuierlich durch diese „Logik“ hindurch. Beim Empfangen eines Ereignisses aus dem Stream reagiert eine Stream-Verarbeitungsanwendung auf dieses Ereignis: Sie kann eine Aktion auslösen, ein Modul oder eine andere Statistik aktualisieren oder sich dieses Ereignisses als zukünftige Referenz „merken“. Streaming-Berechnungen können auch mehrere Datenströme gemeinsam verarbeiten, und jede Berechnung über den Ereignisdatenstrom kann andere Ereignisdatenströme erzeugen.
Vorteile durch die Stream-Verarbeitungsinfrastruktur
Die Systeme, die die Datenströme empfangen und senden sowie die Anwendungs- oder Analyselogik ausführen, werden als Stream-Prozessoren bezeichnet. Die primäre Aufgabe eines Stream-Prozessors besteht darin, sicherzustellen, dass die Daten effizient fließen, dass die Berechnungsaktionen passend skalieren und zudem fehlertolerant sind. Bei Apache Flink handelt es sich um ein ausgereiftes Stream-Verarbeitungs-Framework aus dem Open-Source-Umfeld, das diese Herausforderungen löst.
Das Stream Processing Paradigma adressiert viele Herausforderungen, denen sich Entwickler von Echtzeit-Datenanalysen und ereignisgesteuerten Anwendungen heute konfrontiert sehen:
- Anwendungen und Analysen reagieren sofort auf Ereignisse: Es gibt keine Verzögerungszeit zwischen „Ereignis ist aufgetreten“, „Einsicht ist gewonnen“ und „Aktion ist ausgeführt“. Aktionen und Analysen sind dadurch aktuell und spiegeln die Daten wider, wenn sie noch frisch, aussagekräftig und wertvoll sind.
- Das Stream-Processing kann Datenmengen verarbeiten, die viel größer sind als bei anderen Datenverarbeitungssystemen: Die Ereignisströme werden direkt verarbeitet, und es wird nur die aussagekräftige und somit sinnvolle Teilmenge der Daten erhalten.
- Das Stream-Processing modelliert auf natürliche und einfache Weise die Kontinuität und Aktualität der meisten Daten: Dies ist ein krasser Gegensatz zu geplanten (Batch-)Abfragen und Analysen von statischen/ruhenden Daten. Die schrittweise Berechnung von Updates und nicht die periodische Neuberechnung aller Daten passt besonders gut zum Stream-Processing-Modell.
- Das Stream Processing dezentralisiert und entkoppelt die Infrastruktur: Das Streaming-Paradigma reduziert den Bedarf an großen (und entsprechend teuren) Datenbanken. Stattdessen behält jede Stream-Verarbeitungsanwendung ihre eigenen Daten und Zustände, was durch das Stream-Processing-Framework vereinfacht wird. Auf diese Weise passt eine Stream-Verarbeitungsanwendung natürlich in eine Microservices-Architektur.
Stateful Stream-Processing
Beim stateful Stream-Processing handelt es sich um eine Teilmenge des Stream Processing, bei der die Berechnung den Kontextzustand mitführt. Dieser Zustand wird verwendet, um Informationen zu speichern, die aus den zuvor gesichteten Ereignissen abgeleitet wurden. Praktisch alle nicht-trivialen Stream-Processing-Anwendungen erfordern eine zustandsorientierte Stream-Verarbeitung, wie die folgenden Beispiele belegen:
- Eine Betrugspräventionsanwendung würde die letzten Transaktionen für jede Kreditkarte im Zustand mitführen. Jede neue Transaktion wird mit denjenigen im mitgeführten Zustand vergleichen, die als gültig oder betrügerisch gekennzeichnet sind, und der Zustand wird mit dieser Transaktion aktualisiert.
- Eine Online-Empfehlungsanwendung würde Parameter speichern, die die „Vorlieben“ des Benutzers beschreiben. Jede Produktinteraktion erzeugt ein Ereignis, das diese Parameter aktualisiert.
- Ein Microservice, der eine Song-Playlist oder einen E-Commerce-Einkaufswagen verwaltet, empfängt Ereignisse für jede Benutzerinteraktion mit Songs oder Produkten. Der Zustand führt dabei die Liste aller hinzugefügten Elemente.

Konzeptionell vereint das stateful Stream-Processing die Datenbank- oder Schlüssel/Wert-Speichertabellen und die ereignisgesteuerte bzw. reaktive Anwendungs- oder Analyselogik zu einer eng integrierten Einheit. Die tiefgreifende Integration zwischen dem Zustand und der Ausführung der Anwendungs-/Analyselogik führt zu einer sehr hohen Leistung, Skalierbarkeit, Datenkonsistenz und Bedienerfreundlichkeit.
Das stateful Stream-Processing erfordert einen Stream-Prozessor, der die Zustandsverwaltung unterstützt. Apache Flink bietet dazu professionelle Unterstützung für das stateful Stream-Processing, einschließlich der Fähigkeit, sehr große Zustandsinformationen zu verarbeiten, sowie eine passende Skalierung von zustandsbehafteten Streaming-Programmen, Zustand-Snapshots (für Versionierung und Anwendungs-Updates) sowie Upgrade- und Schema-Evolutionsfunktionen.
Stream Processing vereint Datenverarbeitung, Analytik und Anwendungen
Bisher wurden sowohl Echtzeit-Datenverarbeitung / Analytik, als auch ereignisgesteuerte Anwendungen erwähnt. Man könnte meinen, das sind zwei verschiedene Bereiche, in denen Verarbeitung und Analyse über Frameworks, wie Hadoop oder SQL-basierte Data Warehouses, und Anwendungen über Applikations-Frameworks und Datenbanken implementiert werden.
Doch die aktuellen Ansätze in der Datenverarbeitung bzw. Analytik und die ereignisgesteuerten Anwendungen haben viel gemeinsam. Damit die Analytik ihre Ergebnisse in Echtzeit (oder nahezu in Echtzeit) liefern kann, muss ein System kontinuierlich die Ergebnisse mit jedem Datensatz oder Ereignis berechnen und aktualisieren.
Moderne Anwendungen und Mikroservices arbeiten ebenfalls ereignisgesteuert oder „reaktiv“, d.h. ihre Logik und Berechnung wird durch Ereignisse ausgelöst (wobei Ereignisse erzeugt werden, z.B. durch die Interaktion eines Benutzers mit einer Website). Das Stream-Processing vereinheitlicht Anwendungen und Analysen. Dies vereinfacht die gesamte Infrastruktur, da viele Systeme auf einer gemeinsamen Architektur aufgebaut werden können. Zudem versetzt es einen Entwickler in die Lage, Anwendungen zu erstellen, die analytische Ergebnisse nutzen, um auf Erkenntnisse aus den Daten zu reagieren und direkt zu handeln. Als Beispiele dafür gelten:
- Klassifizierung einer Bank-Transaktion als betrügerisch (auf der Grundlage eines analytischen Modells mit einer automatischen Blockierung der Transaktion),
- Senden von Push-Benachrichtigungen an Benutzer, basierend auf Modellen über deren Verhalten und
- Anpassung der Parameter einer Maschine basierend auf dem Ergebnis einer Echtzeitanalyse ihrer Sensordaten. (rhh)
Hier geht es zu Ververica (ehemals data Artisans)


