Einfaches Entdecken neuer Zusammenhänge in nicht aufbereiteten Daten Data Lake bietet Daten und Analyse für alle
30. Juni 2015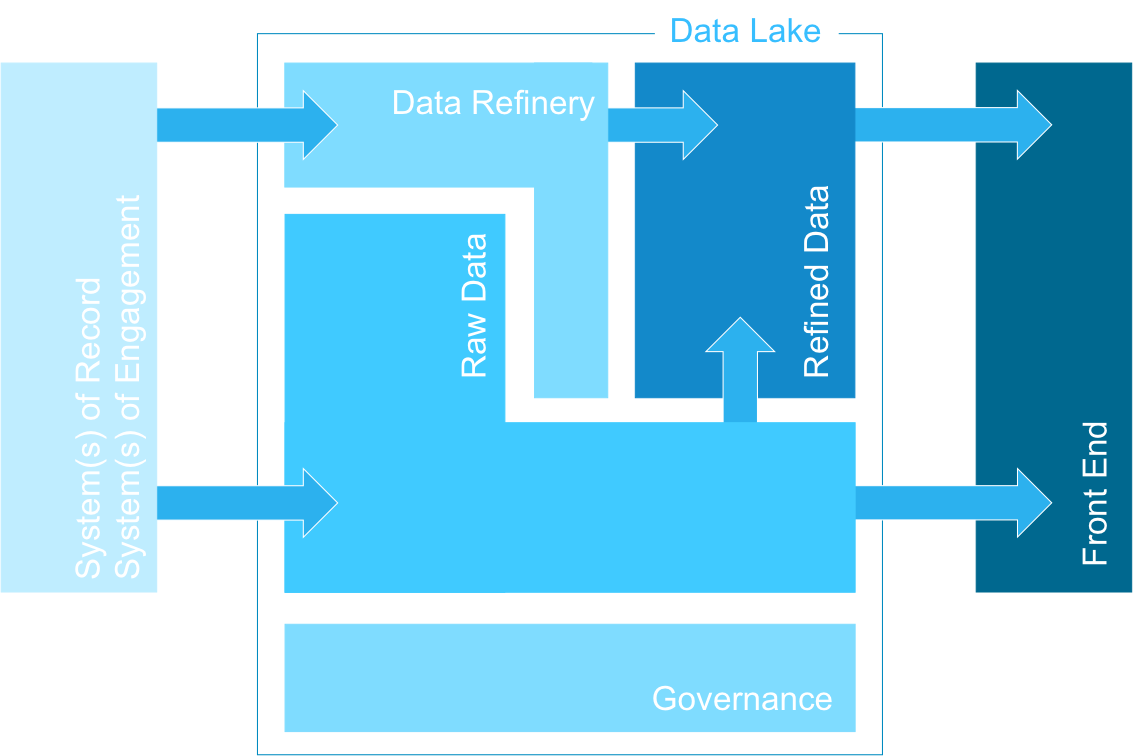
Daten und Informationen spielen in Unternehmen eine immer größere Rolle und sie sind neben Arbeit, Kapital und Umwelt der neue Produktionsfaktor geworden. Kaum ein Begriff hat diesen Bereich so geprägt wie „Big Data“. Dabei geht es keineswegs nur um die Größe der Datenmengen. Vielmehr sind in den letzten Jahren neue Arten von Daten in Unternehmen angefallen, angefangen bei einer zunehmenden Zahl an Sensordaten und technischen Log-Dateien bis hin zu Social Media.
Diese enthalten häufig wertvolle Informationen, werden aber in klassischen Business Intelligence Systemen ignoriert. Big Data bedeutet letztendlich, Nutzen aus einer Vielzahl von Daten oder aus allen verfügbaren Daten zu ziehen. Konzepte wie Data Lake können beim Entdecken neuer Zusammenhänge in nicht aufbereiteten Daten helfen.
Heterogenität

Die Heterogenität der „neuen“ Daten und die schnelle Veränderlichkeit der Formate lässt sich kaum mit klassischen Data Warehouse Prozessen und Methoden abbilden. Hauptursache dafür sind der hohe Vorab-Aufwand für die Datenintegration und die daraus resultierende mangelnde Flexibilität, neue Anforderungen auch sehr kurzfristig und agil umsetzen zu können. Außerdem lassen sich manche Daten nur schwer in klassische, relationale Strukturen überführen. Um diese neuen analytischen Anforderungen zu adressieren, wird immer öfter das Data-Lake-Konzept eingesetzt.
Im Vergleich zum klassischen Data Warehouse ist dies ein Paradigmenwechsel: Wurden traditionell die Daten zunächst mit komplexen Datenqualitäts- und Integrationsverfahren in definierte Strukturen überführt, werden sie beim Data Lake direkt in ihrer Ursprungsform abgelegt. Damit können beliebige Daten schnell und einfach für Analysen nutzbar gemacht und beliebig verknüpft werden. Während beim klassischen Data Warehouse eine hohe (Prozess-)Effizienz für interaktive Analysen und Berichte im Vordergrund steht und die Informationen relativ passgenau für den Benutzer aufbereitet sind, ermöglicht ein Data Lake vor allem das einfache Entdecken neuer Zusammenhänge in nicht aufbereiteten Daten.
Diese in der Data Science verbreitete, „forschungsorientierte“ Vorgehensweise ist vor allem sinnvoll, wenn nicht klar ist, ob Nutzen aus den Daten generiert werden kann. In der Praxis lässt sich feststellen, dass fast immer eine Kombination aus standardisierten Self-Service-Analysen und Data-Science-orientierten Vorgehensweisen erforderlich ist. Der Data Lake ist dabei in einen Rohdatenbereich (Raw Data) und einen Bereich mit aufbereiteten, integrierten und qualitätsgesicherten Daten (Refined Data) unterteilt.
Technologiekombination
Herzstück des Data Lakes ist üblicherweise das Open Source Framework Hadoop. Es kann beliebige Datenarten in großer Menge verarbeiten, wobei die Berechnungen über viele Knoten eines Clusters verteilt werden. Damit eignet es sich ideal, die Rohdaten in ihrer Ursprungsform zu speichern und zu analysieren. Manchmal besteht aber auch die Notwendigkeit, Daten schon vor dem Speichern zu analysieren. Gründe dafür sind zum Beispiel Echtzeitanforderungen (unter anderem aus Analysen resultierende direkt Aktionen, von der Warnung – einem Alert – bis zum vollautomatischen Prozess) oder, dass eine vollumfängliche Speicherung technologisch oder wirtschaftlich nicht sinnvoll ist und nur bestimmte Events herausgefiltert werden sollen beziehungsweise eine Vorverdichtung stattfinden soll. Dafür werden Streaming-Analyse-Systeme wie IBM InfoSphere Streams verwendet, die Analysen direkt im Datenstrom ermöglichen.
Innerhalb des Data Lake werden Daten teilweise aufbereitet, um dem Fachanwender die Arbeit zu erleichtern, indem sie zum Beispiel in dimensionale Modelle überführt, Bestandkennzahlen aus Zu- und Abgängen vorberechnet und Datenqualitätsverfahren angewendet werden. Diese aufbereiteten Daten werden dann oft einer großen Gruppe von Anwendern bereitgestellt. Der aufbereitete Teil des Data Lake entspricht in seinem Konzept im Wesentlichen dem des Data Warehouse.
Daher werden oft klassische Datenbank-Technologien verwendet, wobei der Anspruch der Anwender gerade an die Einfachheit deutlich gestiegen ist. Eine Vielzahl neuer innovativer Produkte – vom hybriden In-Memory Data Warehouse über Data Warehouse Appliances bis hin zu Cloud-Angeboten – adressieren dieses Bedürfnis. Ziel ist vor allem die schnellere Umsetzung neuer Anforderungen, um auf dynamische Veränderungen beispielsweise im Marktumfeld schnell und agiler (re-)agieren zu können.
Die so gewonnene Agilität ist allerdings eine große Herausforderung aus Governance-Sicht. Diese beschränkt sich dabei nicht nur auf Sicherheit, sondern umfasst auch Aspekte wie Nachvollziehbarkeit der Prozesse, Dokumentation der Dateninhalte und Interpretationen oder aber auch Maskierung von Daten für bestimmte Nutzergruppen. Effektive Governance erfordert einen ganzheitlichen Ansatz über den gesamten Prozess und Technologiegrenzen hinweg, um ein komplettes Bild des „Puzzles“ zu erhalten.
Bei allen Technologiediskussionen ist wichtig, den Nutzen immer fest im Blick zu behalten. Neue, flexible Konzepte wie der Data Lake und innovative Produkte wie Hadoop und Streaming-Analysen bieten weit mehr Möglichkeiten als die Modernisierung vorhandener Analyselandschaften. Sie ermöglichen vor allem komplett neue Geschäftsmodelle und -felder.
Das Beispiel des dänischen Windradherstellers Vestas zeigt, wie Technologie ein Geschäftsmodell nachhaltig verändern kann. Aufgrund zunehmenden Preisdrucks und der in Europa hohen Produktionskosten mussten neue Wege gefunden werden, sich im weltweiten Wettbewerb zu differenzieren. Um nicht nur Anlagen zu liefern, sondern Komplettprojekte mit „eingebauter“ Investitionssicherheit, entschied Vestas daher, Big Data zu nutzen, um optimale Standorte für Windkraftanlagen und -parks zu berechnen und diese Ergebnisse Kunden und Vertriebsmitarbeitern zur Verfügung zu stellen.
Vor allem die Genauigkeit der Berechnungen und die Art der genutzten Daten waren entscheidend. Die Genauigkeit hing stark vom Detaillierungsgrad der Basisdaten, in diesem Fall der Windinformationen, ab. Dank des Übergangs vom Wetterballon zu laserbasierter Messtechnologie stehen mittlerweile Werte mit deutlich höherer Präzision und Frequenz zur Verfügung, was zu einer massiven Vervielfachung der Daten führte. Interessant war aber auch die Vielfalt der Daten, die kombiniert werden mussten: Angefangen von Sensordaten wie Wetterinformationen, über historische Informationen von Anlagen bis hin zu Stammdaten wie Karteninformationen. Wesentlich war neben der Performance vor allem das einfache Einbinden neuer Datenformate in ihrer Ursprungsform. Dies entspricht dem Rohdaten-Bereich des Data Lake. Zur Realisierung wurde mit IBM BigInsights eine für den Unternehmenseinsatz entwickelte Hadoop Distribution eingesetzt.
Das Apache Hadoop Framework mit seinem flexiblen Ansatz auf Basis eines verteilten Filesystems bietet sich als eine der Kernkomponenten einer Data-Lake-Architektur an. Daten in verschiedenster Form können hier effizient und kostengünstig abgelegt und für Analysen zur Verfügung gestellt werden. Installation, Betrieb und Wartung eines Hadoop Clusters erfordern allerdings eine nicht zu unterschätzende Menge an Know-how, Aufwand, Zeit und Kosten.
Hadoop-Distributionen nehmen mit optimal aufeinander abgestimmten Open Source-Komponenten – erweitert um sinnvolle, an der Praxis in Unternehmen orientierten Erweiterungen und Tools – einer Hadoop-Implementierung den Schrecken. Dies ermöglicht den Aufbau eines Data Lakes mit optimaler Integration in bestehende Systemlandschaften und macht Hadoop von der Installation bis hin zur fertigen Analyse und Visualisierung fit für den Einsatz im Unternehmen.
Analysen für Alle
Data-Lake-Konzepte versprechen, einem breiten Personenkreis im Unternehmen Zugang zu Daten und Analysen zu ermöglichen. Die darunterliegende Plattform soll Erkenntnisse jenseits der standardisierten BI-Reports ermöglichen und zum kreativen Arbeiten mit den Daten einladen. Genau hier gilt es aber, im Hadoop-Umfeld einige Hürden zu überwinden. Java APIs oder Sprachen wie Pig setzen profunde Programmierkenntnisse voraus. Der entsprechende Skill in Unternehmen wie auch am Markt ist bislang nur begrenzt vorhanden.
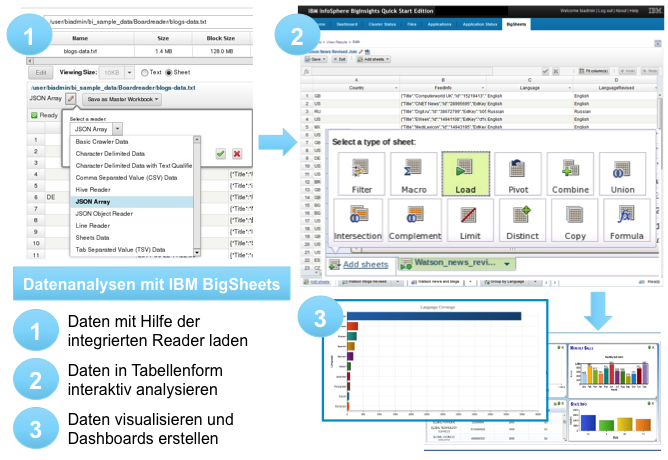
Erfolg versprechen hier Komponenten, welche auf seit vielen Jahren im Unternehmen vorhandenem Know-how aufsetzen, einen schnellen Einstieg in die Welt von Big Data bieten und die Umsetzung von Analysen beschleunigen können. Ein Ansatz dafür sind zum Beispiel Werkzeuge, die ähnlich wie Tabellenkalkulationsprogramme funktionieren, dabei aber die speziellen Anforderungen von Big Data berücksichtigen. Zum einen werden intuitive Importprozesse für typische Daten wie JSON, CSV, TSV oder integrierte Webcrawler benötigt. Zum anderen ist es sinnvoll, Analysen zunächst auf einem kleinen Datenausschnitt (Sample) zu definieren, bevor sie auf den gesamten Datenbestand angewendet werden, was idealerweise automatisiert sein sollte.
Ein weiterer wichtiger Punkt ist die Anbindung von Analyse- und Reporting-Tools. Dies erfordert eine Hadoop SQL-Engine, welche mit Standard JDBC/ODBC-Treibern eingebunden werden kann. Entscheidend ist die ANSI-SQL-Kompatibilität, die die Nutzung vorhandener BI-Werkzeuge auf Hadoop Daten erst ermöglicht.
Neben SQL gewinnen vor allem komplexe, statistische Analysen wie beispielsweise mit R immer mehr an Bedeutung. Die Möglichkeit, R-Code direkt auf Hadoop-Clustern auszuführen, eröffnet dabei komplett neue Anwendungsfelder, erfordert jedoch spezielle Implementierungen von R, da dieses ursprünglich für Einzelplatzsysteme entwickelt wurde. Neben den funktionalen Aspekten sind beim Betrieb eines Hadoop-Clusters aber auch Multi-Tenancy und Workload-Management-Funktionalitäten notwendig, um die verschiedenen analytischen Anforderungen voneinander abgrenzen und Ressourcen effizient zur Verfügung stellen zu können.
Der beste Werkzeugkoffer nützt nichts, wenn nicht die einzelnen Tools geplant und mit Bedacht eingesetzt werden. Bei allen Chancen, die ein Data Lake bietet, sollte das Thema Governance nicht außer Acht gelassen werden. Mehr denn je gilt es, in der Flut an Information nicht den Überblick zu verlieren. Es reicht daher nicht, den Data Lake aufzubauen, indem man Daten aus allen zur Verfügung stehenden Quellen in das zentrale Repository hineinfüllt, sondern es geht darum, die Möglichkeiten dieses Konzeptes richtig zu nutzen. Ohne vernünftiges Information Management und entsprechende Governance wird dies nicht gelingen.
Fragen nach der Quelle, Vertrauenswürdigkeit, Schutz und dem Lifecycle Management der Daten sind wichtiger denn je. Welche Daten sind im Repository vorhanden, wie ist deren Definition und in welchen Kontext stehen sie zueinander sind Informationen, welche einen weiteren Erkenntnisgewinn erst ermöglichen. Leistungsfähige Datenintegrations-Tools mit intelligentem Metadaten-Management ermöglichen die Kontrolle zu behalten und eine Nachvollziehbarkeit der Verarbeitungs-Prozesse zu gewährleisten.
Der Data Lake bietet viele Möglichkeiten, Daten und Informationen in Unternehmen gewinnbringend zu nutzen. Er ermöglicht neben ganz neuen Anwendungsfällen und daraus resultierenden Geschäftsmöglichkeiten vor allem eine „Demokratisierung“ der Daten oder anders gesagt: Die richtigen Daten zur richtigen Zeit zur Verfügung zu haben. Oder wenn dies mal nicht der Fall ist, sie einfach und schnell verfügbar zu machen. Denn die richtige Entscheidungsgrundlage für eine wichtige Entscheidung ist oftmals Gold wert.
Stephan Reimann
ist als Senior IT Specialist Big Data bei IBM Deutschland tätig und
Matthias Reiss
agiert als Senior Client Technical Professional Big Data bei IBM Deutschland.