Advertorial: Flexpod garantiert schnelle BI-Lösungen Zertifizierte Infrastrukturen für Big Data-Applikationen
7. März 2016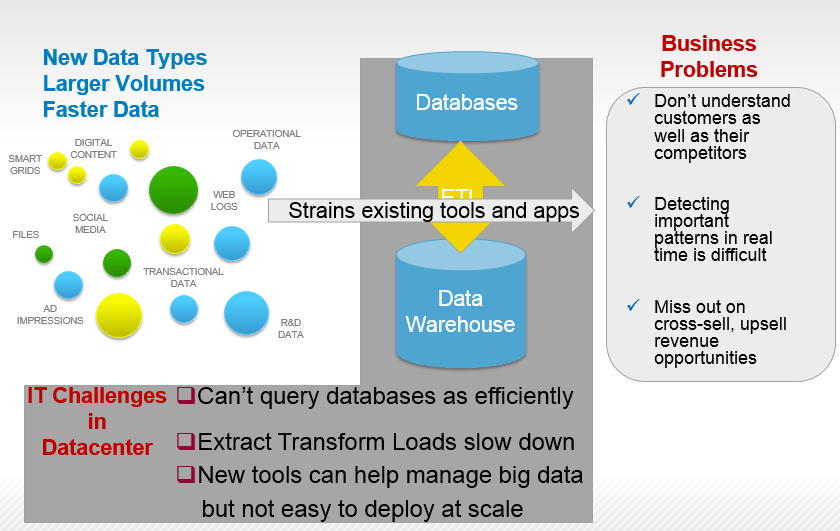
Die Digitalisierung der Unternehmen ändert deren traditionelle Ökosysteme. Um die digitale Transformation möglichst elegant zu meistern, sind neuartige Ansätze gefragt. Dabei gehören die bestehenden Daten einer Organisation bestmöglich ausgenutzt. Generell erweist sich der Bereich „Smart Data Analytics“ als ein hochspannendes Thema – erst recht, wenn man die künftigen Entwicklungen im Umfeld von IoT (Internet of Things) und Industrie 4.0 mit einbezieht. Doch das alles muss zuerst intelligent projektiert und dann technisch umgesetzt werden – eine große Herausforderung für die IT-Abteilungen heutiger Unternehmen. Hier können vordefinierte und vor allem zertifizierte IT-Infrastrukturen wie das Flexpod-Konzept den Zeitaufwand und das Risiko reduzieren, das Unternehmen eingehen, wenn sie Datenanalyse-Anwendungen einsetzen.
BI als Top-Priorität
Die digitale Transformation der Unternehmen gehört zu den Top-Prioritäten der Unternehmenslenker. Wer heute gut aufgestellt ist, der möchte seinen Vorsprung nicht einbüßen, und wer heute der Konkurrenz „hinterher hechelt“, der möchte auf die Überholspur wechseln. Alle Analysten sind sich einig, dass die digitale Transformation nur dann nachhaltig gelingen wird, wenn die Unternehmen die vorhandenen Daten aufbereiten und daraus schnell Entscheidungen ableiten. Doch die aktuell bestehenden Daten stammen oftmals aus verschiedenen Quellen und liegen in unterschiedlichen Formaten vor.
Dazu kommen noch neuartige Datenformate hinzu: Sensoren liefern im Umfeld des IoT (Internet of Things) eine Vielzahl von Informationen, aus Social Media-Kanälen lassen sich wichtige Erkenntnisse – etwa zu Produkteigenschaften – ablesen. Doch dazu muss ein Unternehmen seine Big Data-/Business Intelligence-Umgebung entsprechend aufgebaut haben.
Die Aufgabenstellung im Bereich Big Data/BI kann man in drei Stufen klassifizieren. Im „klassischen BI“ sind historische Daten zusammenzufassen, es gilt sie zu verarbeiten und anschließend zu analysieren. Im Idealfall drückt der „Business Owner“ auf einen Knopf, und ihm werden alle relevanten KPIs geliefert. Damit lässt sich die Standardfrage beantworten: „Wie steht mein Business da?“ Hier kommen umfassende Lösungen wie z.B. SAP, Exact, Tableau, IDS usw. zum Einsatz. Dieser als traditionell zu bezeichnende BI-Ansatz ist in erster Linie „rückwärts gewandt“. Die Ergebnisse sollten allerdings „sekundenschnell“ vorliegen. Allerdings bezieht sich dieses „sekundenschnell“ in erster Linie auf die „Herstellung“, also die Datenermittlung. Wer das einmal pro Monat benötigt – etwa zum Monatsabschluss, der kommt damit gut zurecht. Die Resultate sollten aber „gesichert“ sein, so dass das Ergebnis auch dann vorliegt, falls ein System in der IT-Infrastruktur ausfällt.
Die zweite BI-Gattung betrifft einen weitaus mehr in Richtung Echtzeit konzipierten Ansatz. Dabei geht es in erster Linie noch um strukturierte Daten. Sie werden mittlerweile in In-Memory-Datenbanken, wie z.B. SAP HANA, SQL 2014, etc. abgelegt und dann sehr schnell im Arbeitsspeicher verarbeitet. Je nach Aufgabenstellung sind allerdings sehr viele Daten zu betrachten – einige Unternehmen benötigen Datenvolumina, die sogar im PByte-Bereich liegen. Das passt in der Regel nicht mehr in den Arbeitsspeicher, doch der Zugriff darauf muss sehr schnell erfolgen. Daher müssen hier sehr schnelle Speicher-Systeme bei gleichzeitig hohen Zuverlässigkeitseigenschaften – in diesem Falle „All Flash-Arrays“ – zum Einsatz kommen.
Hier bietet NetApp passende Systeme. Sie sind extrem schnell (im Bereich 1 Million IOPS und mehr) und damit in der Lage, die benötigten Daten mit minimalen Latenzzeiten an die BI-Applikation durchzureichen. Anforderungen an die Sicherheit und Schnelligkeit der Systeme sind essenziell, ein Ausfall von Komponenten würde ein aufwändiges Neustarten der kompletten Berechnungen bedeuten. In einem derartigen „High Performance Business Intelligence System“ werden die Daten in Echtzeit aufbereitet, um schnelle Maßnahmen in der Produktions- und Prozesskette durchzuführen. Doch diese Analyse ist noch nicht nach vorne gewandt.
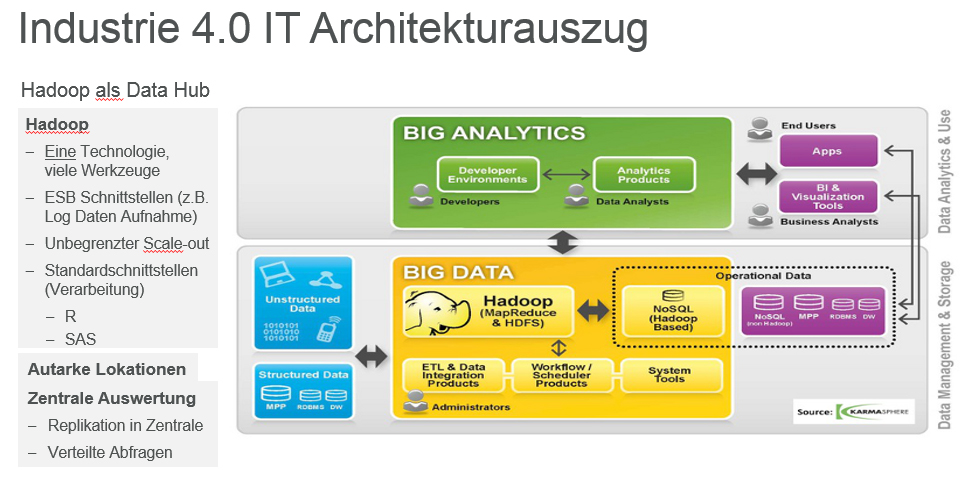
Diese Option kommt beim dritten Ansatz ins Spiel: „Predictive Analytics“. Hier werden nach wie vor die üblichen strukturierten Daten – etwa aus ERP- oder CRM-Systemen, herangezogen. Aber zudem spielen noch andere Daten-Pools mit: Unstrukturierte Daten z.B. aus Social Media-Kanälen, aus einer Vielzahl von stationären und mobilen Quellen, E-Mail-Systemen, etc. Zudem sollten Unternehmen davon ausgehen, dass künftig noch mehr Datenvolumina mit einbezogen werden müssen – IoT lässt grüßen. Vor allem die Sensortechnik wird die Datenmenge massiv nach oben schrauben. Hier können zum Beispiel Unternehmen, die Maschinen herstellen, den Zustand ihrer Produkte im Betrieb beim Anwender überwachen und entsprechende Wartungs- bzw. Austauschzyklen anstoßen, ohne dass eine Komponente erst ausfallen müsste. Dabei zeigt sich exemplarisch der Wert einer „predictive Analyse“ beziehungsweise einer „vorhersagenden“ Betriebsführung. NetApp verwendet dieses Konzept übrigens schon seit langem für die „call home“-Funktion seiner Speichersysteme.
Experten sprechen bereits von Big Data 2.0 – und beziehen sich auf die Datenmengen, die über IoT künftig in die Aufgabenstellung einfließen. Doch diese Daten müssen nach ihrer Zusammenfassung mit Analysesystemen – eigentlich sind es Algorithmen – wie z.B. Mapr, Hortonworks oder Cloudera ausgewertet werden. Damit kann man dann die aktuellen Anforderungen abdecken, doch es gelingt damit auch der Blick in die Zukunft – anhand der relevanten Daten. Diese dritte Variante arbeitet mit strukturierten und unstrukturierten Daten. Das erfordert einen hohen Aufwand beim Datenmanagement, denn es kann bis in die hohen PByte-Kapazitätsbereiche gehen. Nur so lassen sich Aktionen wie „Predictive Operations" mit genauen Vorhersagen treffen.
All diese drei BI-Ansätze haben ihre Berechtigung und ihre Einsatzfelder. Der eine fokussiert sich mehr auf die eher klassischen Unternehmens KPIs, der andere mehr in Richtung dynamischer Datenvolumen – „Ich suche mir Daten aus möglichst vielen Töpfen zusammen, um eine möglichst hohe Kohärenz festzustellen“ – und daraus lassen sich dann sehr viele BI-Services bzw. internen Anwendungsfälle erstellen.
Flexible BI-Infrastruktur
Wenn sich nun die Frage nach den Funktionalitäten der IT-Infrastruktur stellt, die für derartige BI-Anforderungen in den Unternehmen geeignet ist, darf der IT-Verantwortliche einige Kriterien nicht aus den Augen verlieren. Zum einen sind die drei skizzierten BI-Ansätze nicht statisch –sprich Unternehmen werden durchaus den Wechsel von einem zum anderen Modell ins Auge fassen müssen. Eine echte Zukunftssicherheit bietet hier nur ein Konzept, das flexibel genug ist, um eine entsprechende Transformation mitzumachen.
Zum anderen gilt es, verschiedenste Datenquellen und somit Varianzen miteinander zu kombinieren: das sind die klassischen Daten eines Unternehmens, aber auch Daten die anderswo liegen, zum Beispiel in einer Cloud. Das Zusammenführen dieser Daten erfordert eine Speicherschicht, die über ausgetüftelte Datenmanagementfunktionen verfügt und zudem den geforderten Datendurchsatz liefern kann. Hier können die Speichersysteme von NetApp punkten. Sie zeichnen sich durch den effizienten Umgang mit Speicherplatz aus, legen die Daten intelligent wie hochsicher sowohl Vor-Ort, als auch in der Cloud ab und bieten eine enorme Skalierbarkeit. Im Bereich des Data Managements sprechen die hohe Anwendungsflexibilität, die Wahlfreiheit der Datenablage, die Hochverfügbarkeit und die einfache Verwaltbarkeit für die NetApp-Lösungen, die auf dem Speicherbetriebssystem Clustered Data OnTap aufsetzen.
Ein weiteres Argument ist die Standardisierung im Bereich der IT-Infrastruktur. Nur wer vordefinierte und aufeinander abgestimmte Lösungen einsetzt, die zudem in ihrem Zusammenspiel (Server, Netzwerkschicht, Storage-Layer und Verwaltungslösung) zertifiziert sind, kann seine IT-Umgebung schnell produktiv einsetzen. Hier kommt der Flexpod-Ansatz ins Spiel, wie sie NetApp und Cisco im Programm haben.
Die hoch integrierten und standardisierten Flexpod-Komponenten ermöglichen den Anwendern eine vertikale oder horizontale Skalierung, um die Anforderungen ihrer Enterprise-Applikationen zu erfüllen. Dabei lassen sich Leistung, Platzbedarf, nutzbare Kapazität, Performance und Kosten der einzelnen Flexpod-Implementierungen genau planen. Die Flexpod-Familie besteht aus drei grundlegenden Konfigurationen:
Flexpod Express,
Flexpod Datacenter und
Flexpod Select.
Die einfachste Form, Flexpod Select, verspricht kleinen oder mittelständischen Unternehmen eine Kostensenkung und Vereinfachung dank Konsolidierung der IT-Infrastruktur auf einer einheitlichen, einfach zu managenden Plattform. Die Flexpod Express Lösung nutzt die Einstiegs-Komponenten wie Cisco-Server der UCS C-Series, Cisco UCS Mini, Cisco Nexus Switches der Serie 3000 und NetApp Storage der FAS2500 Serie als Basis für ein kleines autonomes Rechenzentrum.
Flexpod Datacenter

Die Lösungen auf der Basis des Flexpod Datacenter sind für größere IT-Umgebungen konzipiert. Sie kombinieren Storage-, Netzwerk- und Serverkomponenten in einer flexiblen Architektur für verschiedene Workloads, wie sie in mittleren und größeren Unternehmen üblich sind. Mit diesen Flexpod-Konfigurationen lässt sich der Aufbau Cloud-basierter Datacenter-Infrastrukturen im eigenen Haus beschleunigen. Zudem bieten diese Systeme die passende Umgebung für geschäftskritische Applikationen – wobei ein Unternehmen dadurch Kosten, Komplexität und Risiken im IT-Bereich verringern kann. Diese konvergente Infrastruktur des Flexpod Datacenter umfasst validierte Designs für Private Clouds auf Enterprise-Ebene sowie für das softwaredefinierte Datacenter (SDDC), horizontal skalierbaren Storage. Das Flexpod Datacenter besteht aus:
NetApp Clustered Data ONTAP und Metro Cluster Software,
herkömmliche sowie horizontal skalierbare All-Flash FAS Unified Storage-Systeme von NetApp,
Cisco Unified Computing System(Cisco UCS)Server, einschließlich UCS Mini,
Cisco Switches der Nexus5000, 6000, 7000 und 9000 Serie sowie
Cisco Application Centric Infrastructure.
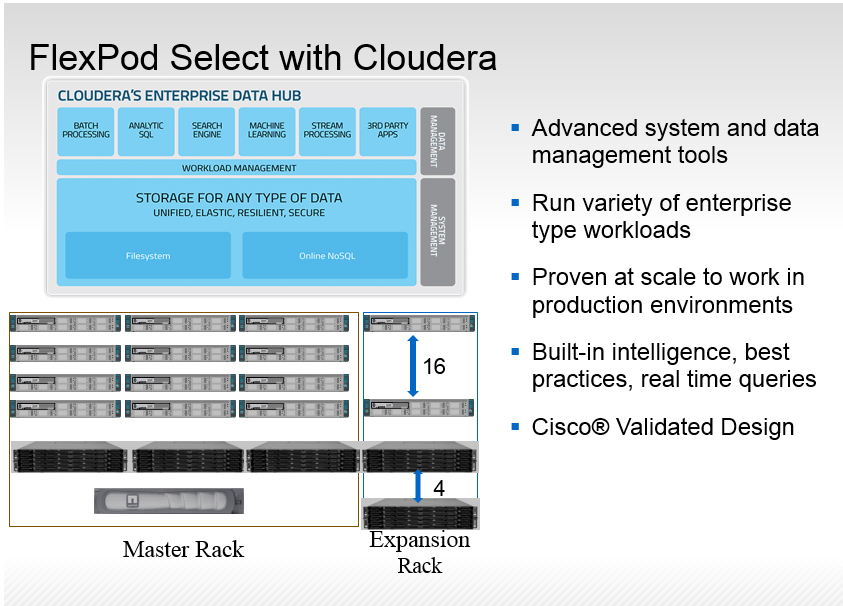
Die Lösungen auf der Basis von Flexpod Select (die dritte Flexpod-Variante) zielen darauf ab, NetApp- und Cisco-Konfigurationen für dedizierte High-Performance Workloads bereitzustellen, die vorab getestet werden. Typische zertifizierte Einsatzszenarien sind Big Data (Analytics), HPC, Datenbanken und Data Warehouses. Diese vorkonfigurierten, skalierbaren Lösungen kombinieren Storage, Networking und Server – sie alle wurden mit analytischen und Datenbankapplikationen validiert. Ein derartiger Ansatz reduziert für Anwenderunternehmen das Projektrisiko, beschleunigt die Implementierung und letztendlich ergibt sich eine weitaus schnellere Amortisierung der Investitionen. Zu den Flexpod Select Komponenten zählen:
NetApp E-Series und EF Series Storage-Systeme,
Cisco Unified Computing System Server und Fabric Interconnect sowie
Cisco Nexus Fabric Extender.
NetApp kooperiert beim Infrastruktur-Support mit Cisco, Cloudera oder Hortonworks beim Hadoop-Support. Dabei erhalten die Anwender Zugriff auf technischen Support zu allen interoperablen Technologien.
Über Referenzarchitekturen adressiert Flexpod sehr stark den Bereich BI/Big Data: Validierte Konfigurationen Flexpod Select mit Cloudera Distribution, einschließlich Apache Hadoop (CDH) und Flexpod Select mit Hortonworks Data Platform (HDP) sind für hochverfügbare Hadoop-Umgebungen der Enterprise-Klasse konzipiert. Für die Kombination Hadoop auf Flexpod Select spricht die höhere Elastizität der Lösung. So können Aufgaben auf den DataNodes auch dann weiterlaufen, wenn einzelne Festplatten ausfallen. Das hat zur Folge, dass ein robuster Schutz für die NameNodes besteht, so dass ein Wiederaufsetzen von Aktionen innerhalb von wenigen Minuten machbar ist – verglichen mit mehreren Stunden, wenn Hadoop mit „Direct Attached Disks“ im Server zum Einsatz kommt.
Ein weiterer Vorteil des Flexpod-Ansatzes zeigt sich in Sachen Wartbarkeit: Festplatten und Knoten können repariert werden, während der das Speichersystem weiterhin läuft. Damit wird einem Datenverlust ein Riegel vorgeschoben. Das führt zu einem schnelleren Abschluss der Jobs und die Daten werden insgesamt gesehen schneller geladen. Damit können die SLAs (Service Level Agreements) für die Fachabteilungen im Unternehmen besser eingehalten werden. (rhh)


